Barbarian
Member
Pizza Guy's question about mutation and information got me thinking. I spent several years working in systems (mostly biological) and considering the issue of general information in populations.
I think few people really understand what information is. Supposedly, Claude Shannon was told to call his measure of message content "information" because "nobody knows what information is."
So let's begin. Keep in mind, there are other theories of information, but it is Shannon's that actually works. The internet would not function without his theory, nor would we be able to communicate across billions of kilometers of space with very low-powered transmitters without his discoveries.
Let's take a look...
Information theory is based on probability theory and statistics. The most important quantities of information are entropy, the information in a random variable, and mutual information, the amount of information in common between two random variables. The former quantity indicates how easily message data can be compressed while the latter can be used to find the communication rate across a channel.
"Entropy", in this case, is the uncertainty of a message. That is, the number of possible states for the message. (bear with me here) If we absolutely know what the message will say, then the entropy will be zero. For example, if a program would always output "Hello, world", the entropy would be zero. On the other hand, if you had a generator that would randomly output letters, then the entropy would be quite high.
If we instead used phenomes (groupings of letters that make specific sounds in English) then the entropy will be lower, since the likelihood of a following letter is somewhat determined by the previous letters.
We can go up to random words, and then random words in the frequency we see in English, and then random words by the probability of following the previous word. All of which decrease intropy. And BTW, decrease information.
What? Yep. A message with low entropy is going to have less information, since you'll learn less when it gets there, than if you couldn't anticipate it at all.
The entropy of a message (or of the gene pool of a population of organisms) is:
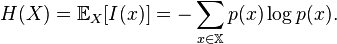
In the case of population genetics, the entropy (H) is found by multiplying the frequency of each allele by the log of the frequency of that allele, and then summing the result for all alleles in the population. And then change the value to a negative.
Suppose there is only one allele:
Then 1.0 X log(1.0) = 1.0 X 0.0 = 0 No information, since we will learn nothing by determining the alllele of an individual.
Suppose there are two alleles, each 50 percent of the population.
0.5 X log(0.5) is about -0.15, changing the sign, we get 0.15. More information, but not a lot more. Each new allele will increase information.
So any new mutation in a population will increase information, not reduce it.
I'll pause for comments.
I think few people really understand what information is. Supposedly, Claude Shannon was told to call his measure of message content "information" because "nobody knows what information is."
So let's begin. Keep in mind, there are other theories of information, but it is Shannon's that actually works. The internet would not function without his theory, nor would we be able to communicate across billions of kilometers of space with very low-powered transmitters without his discoveries.
Let's take a look...
Information theory is based on probability theory and statistics. The most important quantities of information are entropy, the information in a random variable, and mutual information, the amount of information in common between two random variables. The former quantity indicates how easily message data can be compressed while the latter can be used to find the communication rate across a channel.
"Entropy", in this case, is the uncertainty of a message. That is, the number of possible states for the message. (bear with me here) If we absolutely know what the message will say, then the entropy will be zero. For example, if a program would always output "Hello, world", the entropy would be zero. On the other hand, if you had a generator that would randomly output letters, then the entropy would be quite high.
If we instead used phenomes (groupings of letters that make specific sounds in English) then the entropy will be lower, since the likelihood of a following letter is somewhat determined by the previous letters.
We can go up to random words, and then random words in the frequency we see in English, and then random words by the probability of following the previous word. All of which decrease intropy. And BTW, decrease information.
What? Yep. A message with low entropy is going to have less information, since you'll learn less when it gets there, than if you couldn't anticipate it at all.
The entropy of a message (or of the gene pool of a population of organisms) is:
In the case of population genetics, the entropy (H) is found by multiplying the frequency of each allele by the log of the frequency of that allele, and then summing the result for all alleles in the population. And then change the value to a negative.
Suppose there is only one allele:
Then 1.0 X log(1.0) = 1.0 X 0.0 = 0 No information, since we will learn nothing by determining the alllele of an individual.
Suppose there are two alleles, each 50 percent of the population.
0.5 X log(0.5) is about -0.15, changing the sign, we get 0.15. More information, but not a lot more. Each new allele will increase information.
So any new mutation in a population will increase information, not reduce it.
I'll pause for comments.